
The same AI capabilities that make attackers faster can make defenders faster too. Nir Giladi, Security Engineer, provides a look at how Fireblocks Security Posture Management (FSPM) puts adversarial AI agents to work on your policy – finding risky misconfigurations before any attacker can.
—
The asymmetry in digital asset security has always been brutal. Defenders have to be always right, attackers only have to be right once, and once funds reach finality on the blockchain there is no recovery mechanism. AI is making that asymmetry worse.
The same large language models that draft a polished email in seconds also draft a polished spear-phishing email in seconds. The same code-analysis assistants that help developers reason about a codebase help adversaries reason about it too. Voice cloning has crossed the threshold where a few seconds of audio can produce a convincing impersonation of an executive on a phone call. Drainer-as-a-Service operators are increasingly bundling these capabilities into off-the-shelf kits sold on a revenue-share basis.
For institutions managing digital assets, the practical effect is that the cost of an attempted attack has collapsed, while the value of a successful one has not. An adversary that used to need a small team can now run with a single operator and a stack of AI tooling. They can iterate against your perimeter, your people and, increasingly, your configuration at a pace that human-operated defenses were never designed to match.
So the question we’ve been asking ourselves is straightforward: if attackers now have AI working for them around the clock, what does it look like to have AI working against them?
When defense at human speed is the bottleneck
Most of the controls organizations rely on to secure digital asset operations are paced by humans. Quarterly access reviews. Change-approval tickets. Periodic policy audits. Each of these is good practice, yet each of them moves slowly enough that an AI-equipped attacker probing your environment can find a gap weeks or months before your next scheduled review surfaces.
This is especially painful in one specific place: the transaction policy itself. Our analysis of past incidents keeps landing on the same finding. Nearly every theft incident is the result of a transaction that was technically authorized by policy. The signatures verified, the approvals lined up, the policy returned ALLOW. The system did exactly what it was configured to do, and exactly what it was never supposed to allow.
Mature Fireblocks tenants don’t have a single transaction rule. They have tens, layered across vaults, exchange accounts, network connections, fiat accounts, and one-time-addresses. All with different initiators, designated signers, approval quorums, amount and time limits gluing it all together.
The dangerous patterns aren’t single bad rules; they’re emergent behaviors of rules that interact:
- An operator was added to a “low-risk” rule for convenience, and a quirk of the logic now lets them be the sole approver of their own transfers.
- A small-amount ALLOW rule and a “to any address” rule, written months apart by different admins, combine into a path that walks funds out of the vault in chunks under the cap.
- A new exchange connection inherits a rule that wasn’t designed with it in mind, opening a route from cold storage to an external destination nobody intended.
The challenge of identifying a lateral movement between a vault and an outside account across multiple, individually-allowed transactions is exceptionally difficult for human reviewers. This doesn’t scale.
Static rule linting catches syntax issues, not exploits. In a world where adversaries can ingest a configuration description into an LLM and ask “where’s the weakness?”, we cannot afford to be the slower analyst in that exchange.
Use AI where it wins, and ground it where it doesn’t
The case for AI in security is easy to overstate. We’ve all seen products that wrap an LLM around an alert feed and call it innovation, but that isn’t useful. Confidently-wrong “critical findings” are worse than no findings at all because they burn trust and train your team to ignore the tool.
We’ve taken a more deliberate approach. AI shows up in our security stack only where two things are true:
- The problem is genuinely combinatorial. LLMs are good at exploring vast spaces of possibilities – exactly the kind of problem a complex transaction policy presents.
- LLM outputs can be grounded in a deterministic system. LLMs reason; they don’t decide. Every claim an LLM agent makes is validated against a real engine before it can become a finding – which is how we keep hallucinations out of what reaches our customers.
The first place we applied these principles is the policy configuration layer. This is the governance rulebook at the heart of our defense-in-depth security stack. The result is the Agentic Policy Analyzer (APA), a new capability inside FSPM (Fireblocks Security Posture Management) that uses purpose-built LLM-powered agents to adversarially analyze your transaction policy.
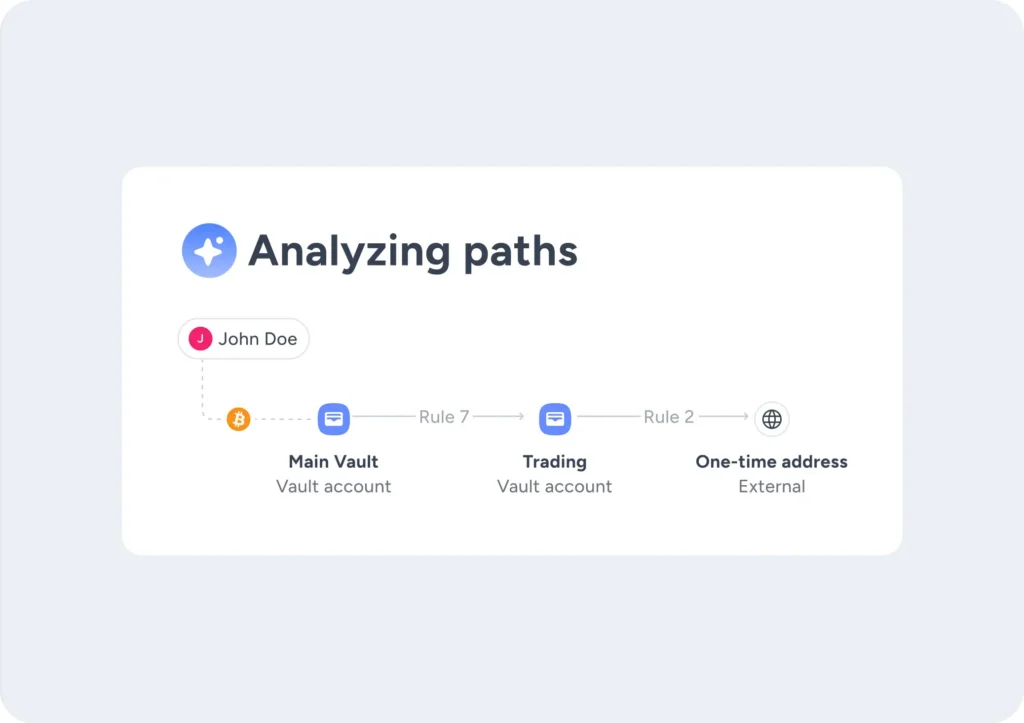
Every time a policy is modified, APA runs an analysis pipeline that asks one question on your behalf: Given this exact policy, how could a malicious actor drain your vaults?
To ensure a hallucination cannot become a finding, every transaction the agent proposes is evaluated against the real policy engine, not the LLM’s interpretation of the rules. If the engine returns a BLOCK response, the hallucinated exploit is discarded. This means an exploit found by APA is a lateral sequence of transactions the policy engine itself accepted. The LLM’s job is to find those paths; it doesn’t get to invent them.
The adherence to the principle that LLMs reason, deterministic systems decide, is what lets us responsibly use AI for defense in a space where the cost of being wrong is irreversible.
Two agents, two attacking mindsets
APA uses two specialized agents to simulate different stages of an attacker’s approach.
Single-Actor Risk Agent
The first agent identifies single points of failure by locating risky users who can initiate, approve, and sign a transaction without a second person. These users are the high-risk targets for credential-theft or social-engineering campaigns.
Adversary Agent: Exploiting a Policy Rule
This agent takes the risky candidates from the first agent and probes the policy in a sandboxed simulation. It forms hypotheses about exploitable rules (or combinations of rules) that could chain individually-allowed transactions into something damaging.
When the agent completes, it returns a full record of every successful exploit it found: which user executed it, which combination of rules made it possible, which transactions were involved, and why each one was allowed. That record is the proof, and it serves as your remediation playbook-pointing the security team directly at the specific rule that needs correction.
What this means in practice
For FSPM customers, the day-to-day experience is straightforward. The multi-week, often-skipped policy review is completely replaced by automated adversarial analysis on every policy change:
- Automated Simulation: The moment a policy change is published, APA picks it up automatically to trigger the agent pipeline.
- Verified Findings: The single-actor risk agent maps the candidates, and the adversary agent attempts to drain funds in a sandboxed simulation to mathematically prove the exploit.
- Actionable Signal: Findings appear directly in FSPM alongside other posture signals, delivering the full reasoning, transaction samples, and the specific rules involved.
Security and operations teams gain a continuous, adversarial view of their configuration, matching the cadence of modern attackers.
Looking Ahead
The threat landscape is not going to slow down. Attackers will continue to operationalize AI for reconnaissance, social engineering, exploit development, and increasingly for analysis of the policies and permissions that govern digital assets operations. The window between configuration change and potential exploit is going to keep shrinking.
Our response will be to keep applying AI on the defender’s side carefully, grounded in deterministic systems, and where it gives us a real edge. These are the first agents in what we expect to be a growing roster. We’re already exploring additional analyzers that model other attack patterns and that operate on different categories of policy, and we’re working on simulation backends that bring even higher fidelity to the adversarial loop.
The underlying philosophy will stay the same. The only people thinking adversarially about your policy should be the people on your side. With the Agentic Policy Analyzer, you have a few more of them working around the clock, at the same speed as your adversaries.
To learn more about FSPM and the Agentic Policy Analyzer, talk to a security expert or visit our security platform page.